Pipelining with a sortfunnel stage
Posted: Thu Jan 15, 2015 8:54 am
We've got a challenging problem in job design where we haven't figured out a solution which doesn't break the pipeline. I've narrowed down the basic problem into a simple example, pictured below.
This job reads a DB2 database with hundreds of millions of records. The data takes some computation on the DB2 database end and is delivered very slowly, say 1000 records per second. The single "ExampleTransform" stage is just a placeholder, in reality there are many other lookups and other processing stages in this location.
The problem revolves around the construct with the lookup stage and the subsequent Sorted funnel stage. When the lookup is successful the data is augmented with a column called "RSK" and goes down "RecordFound", if not then the record goes down "RecordNotFound" where some processing is done to compute a "RSK" value, which is added to the data and the two streams go through the SortedFunnel. The order of records needs to remain unchanged since the data has to remain sorted for later processing.
What is happening at runtime is that when no "RSK" lookup failures occur and no records flow down the "RecordNotFound" link all of the input data is buffered on the "RecordFound" link until the last input record is read, whereupon the sorted funnel stage knows that no records will come along the "CorrectedData" input link and that the buffered data can be passed downstream.
This means that the job runs very slowly indeed since most of the time it is waiting for DB2 and buffering the rows. If the data has rows that flow through "RecordNotFound" the job goes much faster, since whenever a row goes through the "RecordNotFound" link it triggers the buffered values before the SortedFunnel to get passed to the next stage and now DataStage has processing work to do in parallel with the DB2 data feed.
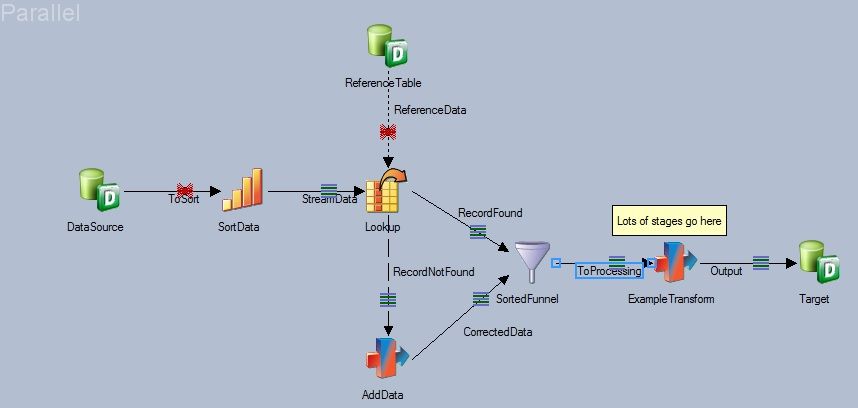
I am looking for a way to do this lookup-reject handling withough having to re-sort the data or wait hours longer than necessary for this job to finish.
This job reads a DB2 database with hundreds of millions of records. The data takes some computation on the DB2 database end and is delivered very slowly, say 1000 records per second. The single "ExampleTransform" stage is just a placeholder, in reality there are many other lookups and other processing stages in this location.
The problem revolves around the construct with the lookup stage and the subsequent Sorted funnel stage. When the lookup is successful the data is augmented with a column called "RSK" and goes down "RecordFound", if not then the record goes down "RecordNotFound" where some processing is done to compute a "RSK" value, which is added to the data and the two streams go through the SortedFunnel. The order of records needs to remain unchanged since the data has to remain sorted for later processing.
What is happening at runtime is that when no "RSK" lookup failures occur and no records flow down the "RecordNotFound" link all of the input data is buffered on the "RecordFound" link until the last input record is read, whereupon the sorted funnel stage knows that no records will come along the "CorrectedData" input link and that the buffered data can be passed downstream.
This means that the job runs very slowly indeed since most of the time it is waiting for DB2 and buffering the rows. If the data has rows that flow through "RecordNotFound" the job goes much faster, since whenever a row goes through the "RecordNotFound" link it triggers the buffered values before the SortedFunnel to get passed to the next stage and now DataStage has processing work to do in parallel with the DB2 data feed.

I am looking for a way to do this lookup-reject handling withough having to re-sort the data or wait hours longer than necessary for this job to finish.